Выведенный статистика
Определение логической статистики
Логическая статистика помогает изучить выборку данных и сделать выводы о ее совокупности. Выборка — это меньший набор данных, взятый из большего набора данных, называемого генеральной совокупностью. Если выборка не представляет население, невозможно сделать точные оценки, относящиеся к последнему. Цель изучения статистики вывода состоит в том, чтобы сделать вывод о поведении населения.
В отличие от выводной статистики, описательная статистика просто описывает набор данных, не помогая делать выводы. В этом контексте говорят, что статистика логического вывода выходит за рамки описательной статистики. Он особенно используется, когда невозможно изучить каждую точку данных генеральной совокупности.
Оглавление
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Ключевые выводы
- Логическая статистика включает в себя выводы для населения, из которого была взята репрезентативная выборка. Выводы делаются на основе анализа пробы.
- Процедура включает в себя выбор выборки, применение таких инструментов, как регрессионный анализ и проверка гипотез, а также вынесение суждений с использованием логических рассуждений.
- Результаты включают ошибку выборки. Эта ошибка возникает, когда исследователь не выбирает выборку, которая представляет генеральную совокупность. Чтобы предотвратить ошибку выборки, необходимо выбрать случайную выборку, прежде чем применять инструменты логической статистики.
- Описательная и дедуктивная статистика — это две ветви статистики. Первый описывает набор данных, а второй помогает делать выводы.
Объяснение выводной статистики
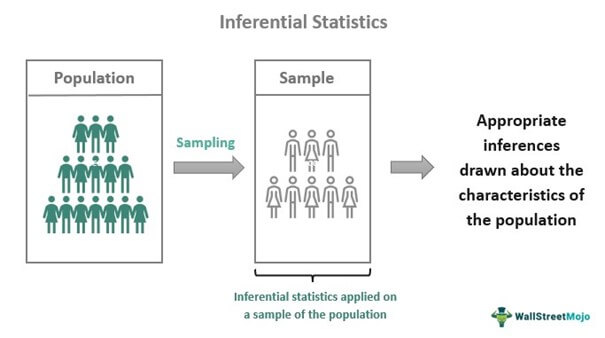
Логическая статистика позволяет исследователям делать обобщения о населении, используя репрезентативную выборку. Однако, поскольку невозможно точно предсказать поведение популяции почти во всех случаях, говорят, что результаты основаны на неопределенности.
Кроме того, ошибка выборкиОшибка выборкиФормула ошибки выборки используется для расчета статистической ошибки, которая возникает, когда лицо, проводящее тест, не выбирает выборку, которая представляет всю рассматриваемую совокупность. Формулу для ошибки выборки = Z x (σ /√n) подробнее можно посмотреть здесь. Эта ошибка возникает, если взятая выборка не представляет всю совокупность. Чтобы предотвратить эту ошибку, перед применением дедуктивной статистики рекомендуется собрать случайную выборку.
Логическая статистика требует логических рассуждений для получения результатов. Процедура достижения результатов сформулирована следующим образом:
- Выборка выбирается из совокупности, которую необходимо изучить. Выбранная выборка должна отражать характер и особенности населения.
- Инструменты логической статистики применяются к образцу для оценки его поведения. К ним относятся модели регрессии и проверка гипотез. Проверка гипотез Проверка гипотез — это статистический инструмент, который помогает измерить вероятность правильности результата гипотезы, полученного после выполнения гипотезы на выборочных данных. Он подтверждает правильность полученных результатов первичной гипотезы. Читать далее модели. Первый состоит из линейной регрессии, номинальной регрессии, логистической регрессии и т. д., а второй состоит из z-теста, t-теста, f-теста, дисперсионного анализа (ANOVA) и т. д.
- Выводы делаются на основе выборки, выбранной на первом этапе. Выводы представляют собой предположения или оценки, относящиеся ко всей совокупности.
Типы
Давайте рассмотрим типы инструментов, используемых в статистике вывода.
#1 – Регрессионный анализ
Он измеряет изменение одной переменной по отношению к другой переменной. Линейная регрессия широко используется в логической статистике.
#2 – Модели проверки гипотез
Это требует создания нулевой и альтернативной гипотезы. Выводы делаются с учетом критического значения, тестовой статистики и доверительного интервала. Доверительный интервал = среднее значение выборки ± критический фактор × стандартное отклонение выборки. читать далее. Проверка гипотезы может быть двусторонней, левосторонней и правосторонней. Модели проверки гипотез состоят из следующих инструментов:
а) Z-тест
Формула Z-testZ-testZ-test применяется для проверки гипотез для данных с большим размером выборки. Он обозначает значение, полученное путем деления стандартного отклонения совокупности на разницу между средним значением выборки и средним значением совокупности. Подробнее используется, когда размер выборки больше или равен 30, а набор данных подчиняется нормальному распределению. Дисперсия населения известна исследователю. Формулы даны следующим образом:
Нулевая гипотеза: H0 : µ=µ0
Альтернативная гипотеза: H1: µ>µ0

где,
- х = выборочное среднее
- м = Среднее значение населенияСреднее значение населенияСреднее значение населения является средним или средним значением всех значений в данной совокупности и рассчитывается как сумма всех значений в совокупности, обозначаемая суммой X, деленная на количество значений в совокупности, которое обозначается N.Подробнее
- σ = стандартное отклонение совокупности
- п = размер выборкиРазмер выборкиФормула размера выборки отражает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера совокупности, критического значения нормального распределения при требуемом уровне достоверности, доли выборки и предела погрешности.Подробнее
б) Т-тест
Т-тестТ-тестТ-тест — это метод определения того, существенно ли отличаются средние значения двух групп друг от друга. Это метод логической статистики, облегчающий проверку гипотез. Читать больше используется, когда размер выборки меньше 30 и набор данных подчиняется t-распределению. Дисперсия населения исследователю неизвестна. Формулы даны следующим образом:
Нулевая гипотеза: H0: μ=μ0
Альтернативная гипотеза: H1: μ>μ0

Представления x̄, μ и n такие же, как указано для z-теста. Буква «s» обозначает стандартное отклонение выборки.
в) F-тест
F-тестF-тестФормула F-теста используется для выполнения статистического теста, который помогает человеку, проводящему тест, определить, имеют ли два набора совокупности, которые имеют нормальное распределение точек данных, одинаковое стандартное отклонение или not.read more проверяет, существует ли разница между дисперсиями двух выборок или популяций. Формулы даны следующим образом:

![]()
 где,
где,![]()
 г) доверительный интервал
г) доверительный интервал
Он предлагает диапазон, в который попадет оценка, если тест будет проведен на популяции. При высоком доверительном интервале можно с уверенностью утверждать, что результаты выборки отражают поведение генеральной совокупности.
Пример
Рассмотрим пример логической статистики.
Мистер А хочет открыть кофейню в Нью-Йорке, США. Для разработки соответствующего меню проводится опрос 300 жителей с целью понять их вкусы и предпочтения. В опросе участвуют люди разного возраста, пола и уровня дохода. После применения инструментов логической статистики результаты формулируются следующим образом:
- 70% женщин любят карамельный макиато.
- 50% жителей любят кофе мокко.
- Почти 100% взрослых любят кофе американо.
- 25% подростков любят кофе латте.
С этими результатами г-н А уверен, что включение всех вышеперечисленных сортов кофе привлечет в его магазин самых разных покупателей. Кроме того, г-н А также хочет добавить новые, инновационные вкусы, чтобы дать своим клиентам богатый опыт питья.
Выводная статистика против описательной статистики
Различия между выводной и описательной статистикой перечислены ниже:
ДифференциаторыИнференциальная статистикаОписательная статистикаОпределениеПомогает делать выводы о совокупности, из которой была взята репрезентативная выборка.Описывает набор данных, показывая сводку точек данных.Инструменты для анализаИспользуемые инструменты представляют собой регрессионный анализ и проверку гипотез. В качестве инструментов используются меры дисперсии (диапазон и стандартное отклонение) и центральной тенденции (среднее значение, медиана и мода). Неопределенность Существует неопределенность, поскольку поведение неизвестной совокупности прогнозируется на основе результатов известной выборки. Эта неопределенность отражается в ошибке выборки. Нет никакой неопределенности, поскольку описываются точки данных, которые были фактически измерены. Применимость Используется, когда невозможно удобно изучить каждую точку данных генеральной совокупности. Он используется, когда требуется числовая сводка или графическое представление точек данных.
Часто задаваемые вопросы (FAQ)
1. Что такое логическая статистика?
Логическая статистика позволяет собрать репрезентативную выборку из населения и установить ее поведение путем анализа.
2. Что такое логическая статистика в исследованиях?
В исследованиях логическая статистика используется для изучения вероятного поведения населения. Выводы делаются на основе имеющихся выборочных данных. После того, как выборка выбрана, исследователь может применять любой инструмент логической статистики в зависимости от цели исследования.
3. Какие существуют типы выводной статистики?
Типы логической статистики включают в себя следующее:
• Регрессивный анализ: Он состоит из линейной регрессии, номинальной регрессии, порядковой регрессии и т. д.
• Проверка гипотез: Он состоит из z-теста, f-теста, t-теста, дисперсионного анализа (ANOVA) и т. д.
4. Почему мы используем логическую статистику?
Логическая статистика используется по следующим причинам:
• Для изучения образца с применением нужного инструмента
• Делать обобщения о генеральной совокупности, из которой была взята выборка.
• Для точного прогнозирования поведения популяции
Рекомендуемые статьи
Это было руководство по логической статистике и ее определению. Здесь мы объясним его типы, примеры и когда его использовать. Вы можете узнать больше о статистике из следующих статей –
- Статистика
- Зависимая переменная
- Линия регрессии
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)