Рассеивание
Дисперсия Значение
В статистике дисперсия (или разброс) — это средство описания степени распределения данных вокруг центрального значения или точки. Это помогает понять распределение данных. Более низкая дисперсия указывает на более высокую точность производственного процесса или измерения данных, тогда как более высокая дисперсия означает более низкую точность.
Можно использовать дисперсию, чтобы понять изменение значений набора данных. Это помогает количественно оценить качество данных. В финансах он позволяет инвесторам определять статистическое распределение вероятной отдачи от своих инвестиций. Диапазон, дисперсия, среднее отклонение и стандартное отклонение являются одними из распространенных показателей дисперсии.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Оглавление
Ключевые выводы
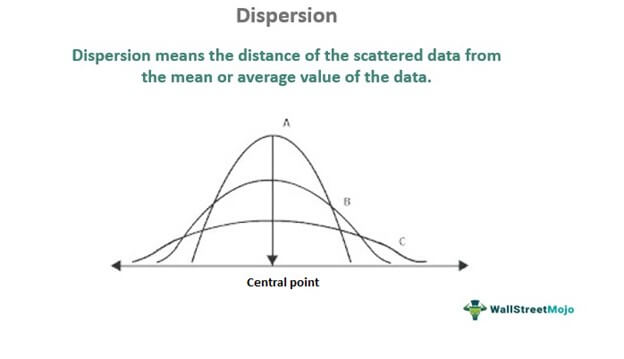
- Дисперсия означает расстояние разбросанных данных от центрального значения данных.
- Он дает информацию о волатильности или энергонезависимости набора данных. Большее расстояние от центральной точки означает более изменчивый характер, и наоборот.
- В финансах дисперсия обратно пропорциональна эффективности, доходности или производительности ценных бумаг.
- Мера дисперсии может быть абсолютной или относительной. Абсолютные показатели имеют ту же единицу измерения, что и данный набор данных, а относительные показатели выражаются в виде отношений и процентов.
Объяснение дисперсии в статистике
Дисперсия (разброс или вариация) может иметь несколько значений в зависимости от контекста, в котором она используется. Например, в статистике это фактор, который помогает определить степень вариации значений в конкретном наборе данных.
В то же время он позволяет инвесторам оценить статистическое распределение потенциальной доходности портфеля. Доходность портфеля. Формула доходности портфеля рассчитывает доходность всего портфеля, состоящего из различных отдельных активов. Формула рассчитывается путем вычисления рентабельности инвестиций в отдельный актив, умноженной на соответствующую весовую категорию в общем портфеле, и сложения всех результатов вместе. Rp = ∑ni=1 Читать далее в финансах. Таким образом, разброс — это измерение изменчивости элемента по сравнению с другими элементами в наборе данных и его центрального значения.
Обычно с помощью меры центральной тенденцииcCentral TendencCentral Tendency — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее, используя 3 различных меры, т. е. среднее значение, медиану и моду. подробнее, чтобы описать определенный набор данных недостаточно. Мера центральной тенденции может помочь узнать среднее значение, медиану или моду наборов данных, но меру вариации можно узнать только через дисперсию. Следовательно, анализ данных с использованием статистики осуществляется:
- Мера центральной тенденции
- Мера рассеивания (MOD)
Измерение спреда дает нам точную информацию о статистике вертикального распределения данных в соответствии с гистограммой. Однако информация, полученная из него, больше связана с разделением точек данных, разницей в значениях набора данных и расстоянием каждой отдельной точки данных от среднего значения всего набора данных.
Другими словами, он показывает, как данные распределены и насколько они отличаются друг от друга, т. е. однородность или неоднородность данных в распределении. Если расстояние между точкой данных и ее средним значением равно:
- Более того, говорят, что набор данных изменчив.
- Меньше, то данные считаются менее изменчивыми, более безопасными или высокодоходными.

Меры дисперсии в статистике
Существует два метода измерения степени изменчивости набора данных:
- Абсолютная мера
- Относительная мера
#1 – Абсолютная мера
Это относится к среднему значению отклонений данных, таких как стандартное отклонение или среднее отклонение. Он имеет ту же единицу измерения, что и исходный набор данных, например, сантиметры, метры, килограммы и т. д. Вот некоторые абсолютные меры разброса.

- Диапазон (клавиша R)
Диапазон относится к разнице между наибольшим и наименьшим значениями в заданном наборе данных. Чем выше значение диапазона, тем выше разброс данных.
Р = Л — Д
где,
L = наибольшее значение
S = наименьшее значение
- Квартильное отклонение (QD)
Квартиль распределяет набор данных по четырем наборам с одинаковыми значениями. Каждый набор данных имеет наименьшее число, наибольшее число и медиану. Q2 или второй квартиль — это медиана данных. Первый квартиль (Q1) соединяет наименьшее число с Q2, а третий квартиль (Q3) соединяет наибольшее число с Q2.
Межквартильный размах – это разница между третьим квартилем и первым квартилем. Половина межквартильного диапазона представляет собой квартильное отклонение.
Следовательно, межквартильный размах (IR) = Q3 – Q1.
![]()
- Коэффициент диапазона (COR)
Это отношение разницы между наибольшим и наименьшим значениями в распределении к сумме наибольшего и наименьшего значений в распределении.
КОР = LS/L+S
где,
L= наибольшее значение
S = наименьшее значение
- Коэффициент вариации (COV)
Он используется для сопоставления двух наборов данных на основе их согласованности.
![]()
где,
Х = среднее
σ = стандартное отклонение
- Коэффициент стандартного отклонения (COS)
Это стандартное отклонение, деленное на среднее значение набора данных.
COS = SD/среднее
где,
SD — стандартное отклонение
- Коэффициент квартильного отклонения (COQ)
Это отношение разницы между третьим и первым квартилем к сумме третьего и первого квартиля набора данных.
COQ = Q3 – Q1/ Q3 + Q1
- Коэффициент среднего отклонения (COM):
Он рассчитывается с использованием среднего значения, медианы или режима данных.
COM = MD/среднее
Или
COM = MD/медиана
Или
COM = MD/режим
где,
MD = среднее отклонение
Примеры
Давайте рассмотрим следующие примеры дисперсии для лучшего понимания концепции.
Пример №1
Возьмем пример с фондового рынка. Рынок акций. Рынок акций работает по основному принципу согласования спроса и предложения посредством аукционного процесса, когда инвесторы готовы заплатить определенную сумму за актив и готовы продать то, что у них есть, по более низкой цене. конкретная цена.читать дальше домен. На бирже торгуется некая ценная бумага А. Трейдеры, которые хотят инвестировать в ценную бумагу А, будут смотреть на ее исторические данные о доходности за последний год. Они оценят степень рассеяния прибыли безопасности за последний год.
Чем меньше степень рассеяния доходностей, тем меньше колебания цен. Таким образом, ценная бумага будет считаться более безопасной инвестицией с низким уровнем риска. Инвестиции с низким уровнем риска. Инвестиции с низким уровнем риска — это финансовые инструменты с минимальной неопределенностью или вероятностью потерь для инвесторов. Хотя такие инвестиции безопасны, они не могут предложить инвесторам высокую прибыль. читать далее. Более того, если степень распространения ценной бумаги А выше, это означает, что цена сильно волатильна. Поэтому ценная бумага будет восприниматься как ненадежная инвестиция в таком случае.
Другими словами, более высокая дисперсия означает более рискованные инвестиции и наоборот.
Пример #2
Рассмотрим два сорта кофе — X и Y с разным выходом.
Кофе X и Y имеют следующие урожаи за шесть месяцев:
Сорт кофеЯнварьФевральМартАпрельМайИюньX363132343033Y584233295020
Чтобы узнать распространение каждого сорта кофе, рассчитаем его ассортимент.
Диапазон (R) = наибольшее значение (L) – наименьшее значение (S)
Сорт кофеНаибольшее значение (L) Наименьшее значение (S) Диапазон (R = L – S)X36306Y582038
Как упоминалось ранее, чем выше диапазон, тем больше разброс данных. Таким образом,
- X имеет более низкий диапазон. Это означает, что у него меньше разбросанных данных или более однородный набор данных.
- Y имеет более высокий диапазон. Он представляет собой сильно разбросанный набор данных или более разнородный набор данных.
Следовательно, X имеет более низкий спред, чем Y. Более низкий спред означает более высокую доходность, а более высокий спред означает более низкую доходность. Следовательно, более высокая дисперсия в данных означает меньшую отдачу, а более низкая дисперсия в наборе данных означает более высокую отдачу.
Часто задаваемые вопросы
Что означает дисперсия в статистике?
Дисперсия означает масштаб распределения данных вокруг центральной точки или значения. Он показывает расстояние значений в распределении от центрального значения. Он играет важную роль в оценке изменчивости, качества и выхода наборов данных при статистическом наблюдении.
Что вызывает дисперсию?
Разброс данных происходит в статистике из-за природных явлений, неравномерного поведения данных наблюдений, а также из-за технических погрешностей приборов измерения данных. Все эти факторы способствуют разбросу данных в статистике.
Каковы три меры дисперсии?
Дисперсия измеряется в абсолютном или относительном выражении. Наиболее часто используемыми показателями разброса являются диапазон, дисперсия и стандартное отклонение. Диапазон — это разница между самым высоким и самым низким значением в распределении. Дисперсия получается путем сложения квадрата разницы между каждым значением в распределении и средним значением, а затем делением его на количество значений в наборе данных. Стандартное отклонение — это квадратный корень из дисперсии.
Рекомендуемые статьи
Это было руководство по дисперсии в статистике и ее значению. Здесь мы обсуждаем меры дисперсии данных в распределении вместе с примерами. Вы можете узнать больше о бухгалтерском учете из следующих статей –
- Нормальное распределение
- Центральная предельная теорема
- Усеченное среднее
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)